Implementando SLOs
- Los SLOs (Service Level Objectives) definen un nivel objetivo de confiabilidad para un servicio.
- Son fundamentales en las prácticas de SRE (Site Reliability Engineer) porque permiten tomar decisiones basadas en datos.
- Una vez comprendidas algunas pautas, crear y refinar SLOs puede ser un proceso directo.
- Se discute la motivación detrás de los SLOs y los presupuestos de error.
- Se incluye una guía paso a paso para comenzar a trabajar con SLOs desde cero.
- También se dan consejos sobre cómo iterar y mejorar los SLOs definidos.
- Se explica cómo los SLOs ayudan a tomar decisiones de negocio efectivas.
- Se abordan temas avanzados sobre la aplicación de SLOs.
- Finalmente, se muestran ejemplos de SLOs para distintos tipos de servicios y consejos para crear SLOs más sofisticados según el contexto.
🚀 ¿Por qué los SREs necesitan SLOs?
- Los ingenieros son un recurso limitado, incluso en las grandes empresas. Por eso, su tiempo debe invertirse en lo más valioso del servicio.
- Establecer un SLO ayuda a equilibrar el desarrollo de nuevas funcionalidades con la necesidad de confiabilidad y escalabilidad.
- Un buen SLO permite priorizar tareas técnicas y tomar decisiones con datos sobre qué tanto se puede comprometer la confiabilidad para avanzar en otras áreas.
- En Google, aprendieron que definir y adoptar SLOs bien pensados es clave para tomar decisiones informadas y priorizar trabajo de forma efectiva.
🔧 Rol del SRE y los SLOs
- El rol del SRE no es solo automatizar todo o reaccionar ante alertas. Su trabajo diario gira en torno a los SLOs.
- Los proyectos del equipo SRE buscan asegurar que los niveles de servicio se mantengan a corto y largo plazo.
- Se afirma incluso que sin SLOs no tendría sentido tener SREs.
🎯 SLOs como herramienta de decisión
- Los SLOs permiten decidir qué trabajos de ingeniería deben priorizarse.
- Por ejemplo, elegir entre automatizar rollbacks o implementar un sistema de replicación puede depender de cómo cada opción impacta el presupuesto de error (error budget).
- Al estimar ese impacto, se puede decidir qué opción beneficia más al usuario final.
- Se sugiere consultar:
- “Decision Making Using SLOs and Error Budgets” (p. 37)
- “Managing Risk” del libro Site Reliability Engineering
🧾 Nota sobre terminología
- En este capítulo, reliability (confiabilidad) se refiere al rendimiento del servicio según sus SLIs. Puede incluir cosas como disponibilidad o latencia.
🛠️ Empezando con los SLOs
- Para establecer un conjunto básico de SLOs, se parte de la idea de que el servicio ya está desplegado y accesible a través de la web.
- Dependiendo del nivel de madurez del sistema, se pueden encontrar tres escenarios comunes:
- Un desarrollo nuevo sin nada aún desplegado (greenfield).
- Un sistema en producción con monitoreo básico, pero sin objetivos claros ni noción de presupuesto de error (y con la expectativa implícita de 100% de disponibilidad).
- Un sistema con un SLO menor al 100%, pero sin entendimiento compartido sobre su importancia ni cómo usarlo para mejorar —lo que se describe como un SLO “sin dientes”.
📈 Requisitos para usar presupuestos de error
Para adoptar un enfoque basado en presupuestos de error, deben cumplirse ciertas condiciones:
- Existen SLOs que todos los involucrados aprueban como adecuados para el producto.
- El equipo responsable del servicio cree que puede cumplir ese SLO bajo condiciones normales.
- La organización se compromete a usar el presupuesto de error como guía para tomar decisiones y priorizar. Esto se formaliza en una política.
- Hay un proceso establecido para revisar y mejorar los SLOs con el tiempo.
⚠️ Si no se cumplen estas condiciones, el cumplimiento de los SLOs será solo otro KPI o métrica de reporte, no una herramienta real para tomar decisiones.
🎯 Objetivos de Confiabilidad y Presupuestos de Error
- El primer paso para definir un SLO adecuado es entender qué nivel de confiabilidad espera el usuario final.
- Un SLO define un umbral: por encima de ese nivel, los usuarios estarán satisfechos; por debajo, aumentan las quejas o abandonos.
- La felicidad del usuario es lo que realmente importa: usuarios felices usan el servicio, generan ingresos, demandan menos soporte y lo recomiendan.
😕 Pero la felicidad del usuario es difícil de medir. Entonces, ¿por dónde empezar?
❌ ¿Por qué 100% no es un buen objetivo?
- Apuntar al 100% de confiabilidad no es realista ni eficiente:
- Incluso con redundancia y checks automáticos, siempre hay probabilidad de falla simultánea.
- La experiencia completa del usuario depende de múltiples sistemas conectados que también pueden fallar.
- Cuanto más te acercás al 100%, mayor es el costo y menor es el beneficio adicional.
- Si lográs 100% de disponibilidad, no podrás realizar cambios:
- Cualquier actualización (features, parches, hardware) puede romper esa perfección.
- La principal fuente de fallos son justamente los cambios.
🔁 Tener un SLO del 100% te vuelve reactivo. Solo podés actuar cuando ya algo falló, no antes.
🧑💼 Quién debe ser responsable del SLO
- Una vez definido un SLO menor al 100%, alguien debe ser responsable de gestionarlo.
- Esa persona debe tener poder para equilibrar velocidad de desarrollo y confiabilidad.
- En empresas chicas: normalmente el CTO.
- En empresas grandes: suele ser el product owner o product manager.
📏 Qué medir: Usando SLIs
- Una vez descartado el 100% como objetivo, el siguiente paso es preguntarse qué medir exactamente.
- Acá entran en juego los SLIs (Service Level Indicators), que son indicadores cuantitativos del nivel de servicio ofrecido.
- Se recomienda calcular los SLIs como una razón: eventos buenos / total de eventos.
📊 Ejemplos de SLIs
- Solicitudes HTTP exitosas / solicitudes HTTP totales (tasa de éxito)
- Llamadas gRPC completadas en < 100 ms / total de llamadas gRPC
- Resultados de búsqueda que usaron todo el corpus / total de resultados (incluyendo los que degradaron bien)
- Consultas de stock con datos recientes / total de consultas de stock
- "Minutos de usuario buenos" según ciertos criterios / total de minutos de usuario
🔄 Propiedades útiles de los SLIs
- Los SLIs expresados como proporciones entre 0% (nada funciona) y 100% (nada falla) son intuitivos y fáciles de manejar.
- Esta forma de medir se adapta bien a la idea de presupuesto de error:
- Si tu SLO es de 99.9%, entonces tu presupuesto de error es del 0.1%.
- Ejemplo: un servicio con 3 millones de solicitudes y un SLO de 99.9% tiene margen para 3,000 errores.
- Si una caída provoca 1,500 errores, consume el 50% del presupuesto de error.
🧰 Ventajas de estandarizar SLIs
- Tener SLIs con el mismo formato (numerador, denominador y umbral) permite aprovechar mejor las herramientas:
- Alertas automáticas
- Análisis de SLOs
- Cálculo de presupuesto de error
- Informes uniformes
✅ La simplificación también es una ventaja adicional.
🧪 Especificación vs. Implementación de SLIs
- Al definir SLIs por primera vez, es útil dividir entre:
- SLI specification: Qué resultado del servicio importa al usuario, sin importar cómo se mida. Ejemplo: "Porcentaje de solicitudes a la home que cargan en menos de 100 ms".
- SLI implementation: Cómo se mide ese resultado en la práctica.
🔧 Ejemplos de implementación para el mismo SLI:
- Medir desde los logs del servidor: rápido pero ignora errores antes del backend.
- Medir con probes que ejecutan JavaScript en un navegador virtual: detecta más errores, pero puede perder problemas específicos de ciertos usuarios.
- Medir desde el propio JavaScript de la home y reportar a un servicio de telemetría: refleja mejor la experiencia del usuario, pero requiere más infraestructura.
📌 Una especificación SLI puede tener múltiples implementaciones, cada una con diferentes costos, precisión y cobertura.
🧭 Primeros pasos con SLIs y SLOs
- No es necesario que tu primer intento sea perfecto; lo importante es empezar a medir y crear un ciclo de feedback para iterar.
- Se desaconseja basar el SLO directamente en el rendimiento actual, ya que puede ser demasiado exigente a futuro. Sin embargo, puede servir como punto de partida si no hay otra referencia.
📌 Elegí SLIs clave para empezar
- Comenzá con aspectos importantes para tu servicio: disponibilidad, latencia, frescura de datos, durabilidad, etc.
- Si no sabés por dónde empezar:
- Elegí una sola app para definir SLOs.
- Identificá claramente quiénes son tus usuarios.
- Pensá cómo interactúan con el sistema y qué tareas críticas realizan.
- Dibujá un diagrama de alto nivel con componentes clave, flujos de datos y dependencias críticas.
🎯 Lo ideal es elegir métricas relevantes y fáciles de medir. Podés empezar simple e ir refinando.
🧱 Tipos de componentes
Una buena forma de empezar a definir SLIs es dividir el sistema en tipos de componentes. Esto permite aplicar métricas más relevantes según la naturaleza de cada parte.
🔁 Request-driven
- El usuario genera un evento y espera una respuesta.
- Ejemplo típico: servicio HTTP o API donde el usuario interactúa con un navegador o una app móvil.
🔄 Pipeline
- Procesa datos de entrada, los transforma y los deja en otro lugar.
- Puede ser un proceso simple en tiempo real o uno por lotes y multietapa.
- Ejemplos:
- Lectura periódica desde una base relacional hacia un hash distribuido.
- Servicio de procesamiento de video entre formatos.
- Análisis de logs de múltiples fuentes.
- Sistema de monitoreo que recolecta métricas remotas y genera alertas.
🗃️ Storage
- Acepta datos (bytes, archivos, videos, etc.) y los guarda para ser accedidos más tarde.
🎮 Ejemplo práctico: Arquitectura de un juego móvil
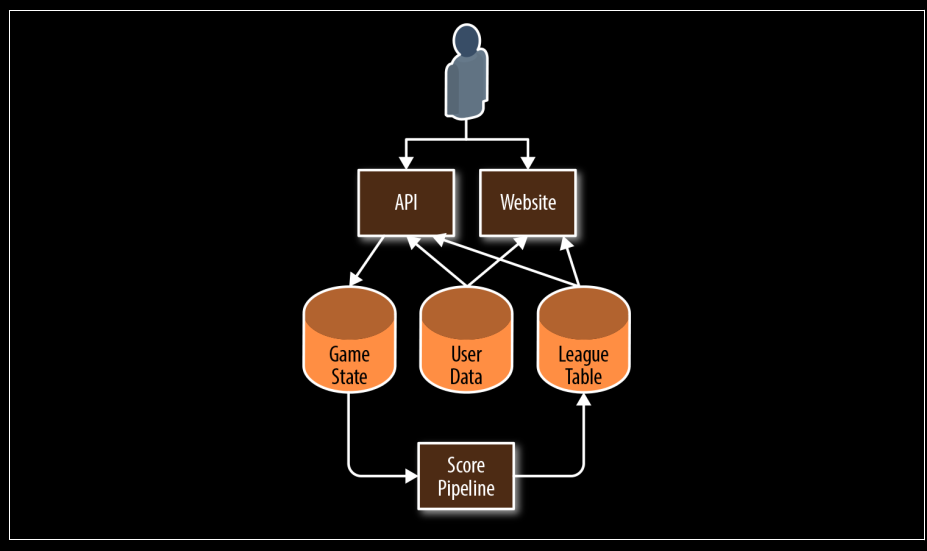
- Se presenta una arquitectura simplificada de un juego móvil:
- Un usuario interactúa con una API o un sitio web.
- Estos acceden a sistemas como Game State, User Data y League Table.
- Una Score Pipeline procesa los datos y actualiza las tablas de puntuación.
- La app usa una API que guarda cambios de estado. La pipeline genera rankings periódicos (por día, semana, etc.), los cuales se muestran en la app y web.
- Los avatares personalizados también se almacenan y usan tanto en la app como en la web.
🧭 SLIs recomendados para esta arquitectura
- Hay que identificar cómo interactúan los usuarios y qué partes impactan su experiencia.
- Algunos componentes pueden compartir SLIs similares (ej. disponibilidad o durabilidad).
- Se recomienda empezar con pocos SLIs clave (cinco o menos), centrados en funcionalidades críticas.
🕒 Múltiples niveles de SLOs
- Para capturar tanto la experiencia típica como los extremos, se pueden usar varios umbrales en un mismo SLO.
- Ejemplo de latencia:
- 90% de solicitudes < 100 ms
- 99% < 400 ms
- Esto ayuda a medir mejor el impacto en la satisfacción del usuario.
- Ejemplo de latencia:
📑 Tabla de SLIs sugeridos según tipo de componente
| Tipo de servicio | Tipo de SLI | Descripción |
|---|---|---|
| Request-driven | Availability | Proporción de solicitudes que recibieron respuesta exitosa. |
| Request-driven | Latency | Proporción de solicitudes más rápidas que un umbral definido. |
| Request-driven | Quality | Proporción de respuestas servidas sin degradación cuando el sistema falla. |
| Pipeline | Freshness | Qué tan reciente es la información accedida por el usuario. |
| Pipeline | Correctness | Proporción de registros procesados correctamente. |
| Pipeline | Coverage | Proporción de trabajos que procesaron suficientes datos o en tiempo. |
| Storage | Durability | Proporción de datos escritos que pueden ser leídos exitosamente. |
📌 En SLIs de durabilidad hay que tener cuidado: el usuario puede requerir solo una parte del total almacenado (ej. datos recientes), y fallar en eso puede generar insatisfacción incluso si la mayoría de los datos están bien.
🔄 De la especificación a la implementación de SLIs
- Una vez definidas las especificaciones de SLIs, hay que decidir cómo medirlas realmente.
- Elegí empezar con opciones que requieran poco esfuerzo técnico. Por ejemplo, usar logs existentes en lugar de implementar probes o instrumentación de frontend.
- Para medir:
- Disponibilidad, necesitás saber si la respuesta fue exitosa (status codes).
- Latencia, necesitás conocer el tiempo de respuesta.
En entornos en la nube, esta información puede estar disponible en dashboards de monitoreo ya integrados.
📡 API y servidor HTTP – Disponibilidad y latencia
- Se mide el éxito en base al status HTTP:
- Códigos 5XX se consideran errores.
- Todo lo demás se toma como éxito.
- Fuentes comunes de SLIs:
- Logs del servidor de aplicación
- Monitoreo del balanceador de carga
- Monitoreo tipo “caja negra”
- Instrumentación del lado del cliente
Nuestro ejemplo usa el balanceador porque refleja mejor la experiencia del usuario.
🔁 Pipeline – Actualización, cobertura y corrección
🕒 Freshness (actualización)
- El pipeline guarda una marca de tiempo (watermark) cada vez que actualiza la tabla de puntuaciones.
- Ejemplos de implementación:
- Consultas periódicas para contar cuántos registros son recientes vs. totales.
- Clientes que validan el “freshness” y registran si los datos estaban actualizados.
Se prefiere instrumentación del lado del cliente, por su mejor relación con la experiencia real del usuario.
📦 Coverage (cobertura)
- El pipeline exporta:
- La cantidad de registros que debería haber procesado.
- La cantidad de registros que efectivamente procesó.
- Puede ignorar registros que no conocía (por mala configuración).
✔️ Correctness (precisión)
- Dos estrategias:
- Inyectar datos conocidos y comparar si el output es correcto.
- Usar un sistema externo que calcule los outputs correctos desde inputs conocidos.
En el ejemplo, se usa un conjunto de datos curado manualmente con outputs esperados.
El SLI es la proporción de outputs correctos durante cada ejecución del pipeline.
📏 Medición de SLIs con monitoreo de caja blanca
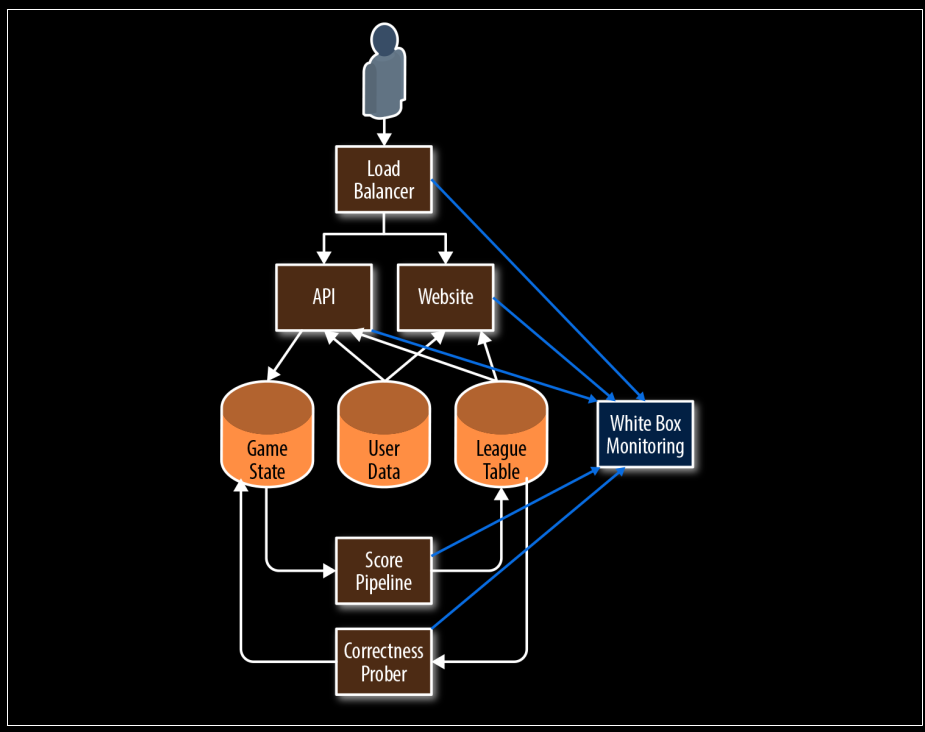
- Se presenta cómo un sistema de monitoreo de caja blanca recolecta métricas desde los distintos componentes del sistema de ejemplo (juego móvil).
- Este sistema recopila información desde:
- Load Balancer
- API
- Website
- Game State, User Data y League Table
- Score Pipeline
- Correctness Prober
📊 Estas métricas se usan para calcular los SLOs iniciales, como disponibilidad y latencia, aunque los mismos principios aplican a cualquier otro tipo de SLO.
- Todos los ejemplos usan notación de Prometheus.
- Para una lista completa de métricas utilizadas, se remite a Appendix A.
🌐 Métricas del balanceador de carga
- Para calcular los SLIs, se usan métricas extraídas del balanceador de carga, agrupadas por backend (
apioweb) y código de respuesta. - Ejemplo de métrica de error (HTTP 500):
http_requests_total{host="api", status="500"}
- La latencia total se mide usando un histograma acumulativo, donde cada bucket representa la cantidad de solicitudes que tardaron menos o igual a un tiempo dado:
http_request_duration_seconds{host="api", le="0.1"}http_request_duration_seconds{host="api", le="0.2"}http_request_duration_seconds{host="api", le="0.4"}
Aunque sería ideal contar directamente las solicitudes lentas, los histogramas permiten una aproximación útil.
- Alternativamente, se pueden definir umbrales explícitos (por ejemplo, 100 ms y 500 ms) dentro del balanceador, aunque esto requiere más configuración y es más difícil de modificar luego.
🧮 Cálculo de SLIs (últimos 7 días)
-
Disponibilidad: proporción de solicitudes exitosas vs. totales:
sum(rate(http_requests_total{host="api", status!~"5.."}[7d])) /sum(rate(http_requests_total{host="api"}[7d])) -
Latencia: percentiles de duración de solicitud:
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[7d]))histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[7d]))
Estas fórmulas permiten observar disponibilidad y latencia en forma agregada a lo largo de una semana.
📌 Usando SLIs para calcular SLOs iniciales
- Una vez que se tienen los SLIs, se pueden redondear a valores manejables para definir SLOs iniciales.
- Se sugiere usar dos cifras significativas para disponibilidad y múltiplos de 50 ms para latencia.
📊 Ejemplo de métricas del API en 4 semanas:
- Solicitudes totales: 3.663.253
- Solicitudes exitosas: 3.557.865 → Disponibilidad del 97.123%
- Latencia (percentil 90): 432 ms
- Latencia (percentil 99): 891 ms
🎯 SLOs propuestos para el API
| Tipo de SLO | Objetivo |
|---|---|
| Disponibilidad | 97% |
| Latencia | 90% de solicitudes < 450 ms |
| Latencia | 99% de solicitudes < 900 ms |
🔗 Para ver un ejemplo completo de documento SLO con implementaciones de SLI, consultar el Appendix A.
🧮 Presupuesto de error para 4 semanas
| SLO | Fallas permitidas |
|---|---|
| 97% de disponibilidad | 109.897 |
| 90% de solicitudes < 450 ms | 366.325 |
| 99% de solicitudes < 900 ms | 36.632 |
Con estos límites se puede monitorear el cumplimiento y tomar decisiones basadas en confiabilidad.
⏳ Cómo elegir una ventana de tiempo adecuada
Los SLOs pueden definirse sobre distintas ventanas temporales. Las dos más comunes son:
🌀 Rolling window (ventana móvil)
- Se alinea mejor con la experiencia del usuario.
- Evita “olvidar” incidentes ocurridos justo antes de cambiar de mes.
- Se recomienda usar un múltiplo de semanas (ej. 4 semanas) para incluir siempre la misma cantidad de fines de semana.
- Ideal si el tráfico de fines de semana y días de semana difiere mucho, ya que evita variaciones innecesarias en los SLIs.
📅 Calendar window (ventana alineada al calendario)
- Más útil para planificación de negocios y proyectos.
- Ejemplo: evaluar SLOs trimestralmente para decidir reasignación de recursos.
- Introduce incertidumbre: a mitad del trimestre no se sabe cuántas solicitudes vendrán en el resto, dificultando estimaciones del error budget.
⚡ Ventanas más cortas
- Permiten tomar decisiones más rápido:
- Si se falla un SLO semanal, se pueden priorizar bugs o tareas relevantes en tiempo.
- Ayuda a prevenir violaciones más grandes en las semanas siguientes.
📐 Recomendaciones y monitoreo
- Ventanas más largas ayudan a decisiones estratégicas:
- Evaluar cambios mayores (bases distribuidas, automatización de despliegues, etc.) requiere datos de más de una semana.
- El esfuerzo de análisis debe ser proporcional al esfuerzo de ingeniería involucrado.
- Se recomienda una ventana móvil de 4 semanas como valor general por defecto.
- Acompañada de resúmenes semanales para priorización de tareas.
- Informes trimestrales para planificación de proyectos.
🧮 Evaluar el desempeño real
- Si la fuente de datos lo permite, podés evaluar el cumplimiento real del SLO en la ventana seleccionada:
- ¿Se cumplieron los objetivos?
- ¿Qué días se falló?
- ¿Coincide con incidentes reales?
- ¿Se tomaron medidas esos días?
🛠️ ¿Sin métricas históricas?
- Si no hay logs ni métricas, configurá una fuente de datos:
- Por ejemplo: usar un servicio de monitoreo remoto que haga health checks (ping o HTTP GET) y cuente respuestas exitosas.
- Muchas herramientas online ofrecen esta funcionalidad fácilmente.
Lograr el acuerdo de los interesados
Para que un SLO propuesto sea útil y efectivo, necesitás que todos los interesados estén de acuerdo:
- Los product managers deben aceptar que ese umbral es lo suficientemente bueno para los usuarios; un rendimiento por debajo de ese valor es inaceptable y merece dedicar tiempo de ingeniería para solucionarlo.
- Los desarrolladores deben estar de acuerdo en que, si se agota el presupuesto de errores, tomarán medidas para reducir el riesgo a los usuarios hasta que el servicio vuelva a estar dentro del presupuesto (como se discute en “Establecer una política de presupuesto de errores”).
- El equipo responsable del entorno de producción debe aceptar que ese SLO es defendible sin un esfuerzo sobrehumano, trabajo excesivo ni agotamiento — todos factores que dañan la salud del equipo y del servicio a largo plazo.
Una vez que todos estos puntos están acordados, lo más difícil ya está hecho. Comenzaste tu camino con los SLOs, y los pasos siguientes consisten en iterar a partir de este punto inicial.
Para defender tu SLO, tendrás que configurar monitoreo y alertas (ver Capítulo 5), de modo que los ingenieros reciban notificaciones a tiempo sobre amenazas al presupuesto de errores antes de que se conviertan en déficits.
Establecer una política de presupuesto de errores
Una vez que tenés un SLO, podés derivar de él un presupuesto de errores. Para poder usar este presupuesto, necesitás una política que defina qué hacer cuando el servicio lo agota.
🔑 Aprobación de la política
Lograr que todos los interesados (product manager, equipo de desarrollo y SREs) aprueben la política es una buena prueba de si los SLOs son adecuados:
- Si los SREs creen que el SLO no es sostenible sin esfuerzo excesivo, pueden proponer objetivos más relajados.
- Si el equipo de desarrollo o el product manager piensan que dedicar más recursos a la confiabilidad afecta negativamente la velocidad de entrega, pueden sugerir ajustar los objetivos. (Reducir los SLOs también reduce la cantidad de incidentes que ameritan intervención).
- Si el product manager considera que muchos usuarios sufrirán una mala experiencia antes de que se actúe según la política, los SLOs probablemente estén demasiado relajados.
Si las tres partes no están de acuerdo en aplicar la política, hay que revisar y ajustar los SLIs/SLOs hasta que todos estén conformes.
🧭 Toma de decisiones
Al aplicar una política de presupuesto de errores, significa que al agotarlo (o estar cerca), se deben tomar acciones para estabilizar el sistema.
Es clave tener una política escrita que defina:
- Qué acciones tomar si se consume todo el presupuesto en un período determinado.
- Quién es responsable de ejecutarlas.
👥 Ejemplos de responsabilidades y acciones comunes
- El equipo de desarrollo da prioridad máxima a bugs relacionados con confiabilidad de las últimas 4 semanas.
- El equipo se dedica exclusivamente a mejorar la confiabilidad hasta volver a estar dentro del SLO, y tiene respaldo para rechazar nuevas funcionalidades.
- Se aplica una congelación de producción, evitando ciertos cambios hasta que el presupuesto vuelva a estar disponible.
⚠️ Desacuerdo entre partes
Si se agota el presupuesto pero no todos los interesados creen que se debe aplicar la política, se debe volver a la etapa de aprobación y revisión de la política.
Documentación del SLO y la política de presupuesto de errores
Un SLO bien definido debe documentarse en un lugar visible y accesible para que otros equipos y partes interesadas puedan revisarlo.
📄 Documentación del SLO
Debe incluir la siguiente información:
- Autores, revisores técnicos y aprobadores (quienes tomaron la decisión de negocio).
- Fecha de aprobación y fecha prevista de próxima revisión.
- Descripción breve del servicio para brindar contexto.
- Detalles del SLO: objetivos y cómo se implementan los SLIs.
- Cálculo y consumo del presupuesto de errores.
- Justificación de los valores elegidos: si se basan en datos experimentales, observacionales o si son ad hoc (esto último debe aclararse para evitar malas decisiones futuras).
📆 La frecuencia de revisión del SLO depende de la madurez del equipo:
- Si están empezando: revisar mensualmente.
- Con experiencia: revisar trimestralmente o menos.
📜 Documentación de la política de presupuesto de errores
Debe incluir:
- Autores, revisores y aprobadores.
- Fecha de aprobación y fecha de próxima revisión.
- Descripción del servicio para contexto.
- Acciones a tomar cuando se agote el presupuesto.
- Ruta clara de escalamiento en caso de desacuerdo (sobre los cálculos o sobre si las acciones aplican al contexto).
- Si el público no tiene experiencia con presupuestos de errores, incluir una introducción conceptual puede ser útil.
📚 Ver el Apéndice A para un ejemplo de documento de SLO y política de presupuesto de errores.
Dashboards y Reportes
Además de los documentos publicados del SLO y la política de presupuesto de errores, es útil contar con reportes y dashboards que brinden una visión actualizada del cumplimiento de los SLOs de tus servicios. Estos son valiosos tanto para comunicarte con otros equipos como para detectar áreas problemáticas.
📊 Reportes de cumplimiento
Un reporte puede mostrar el cumplimiento general de varios servicios, como:
- Si cumplieron con todos sus SLOs trimestrales durante el año anterior.
- Si los SLIs están en tendencia ascendente o descendente en comparación con el trimestre anterior y el mismo trimestre del año pasado.
- Ejemplo:
(5/6)indica que el servicio cumplió 5 de 6 objetivos.
📌 Estos reportes ayudan a visualizar rápidamente qué servicios están en riesgo o necesitan atención.

📈 Dashboards de tendencias
Los dashboards de SLIs permiten:
- Ver si estás consumiendo presupuesto de errores más rápido de lo normal.
- Identificar patrones o tendencias que podrían requerir intervención.
🧯 Dashboards de eventos y consumo de presupuesto
Los dashboards también pueden mostrar:
- Cuánto presupuesto fue consumido por un evento puntual (por ejemplo, un incidente que consumió el 15% del presupuesto en dos días).
- Un ranking de incidentes ordenados por consumo de presupuesto.
Ejemplos útiles:
- “Esta caída consumió el 30% del presupuesto trimestral.”
- “Estos fueron los tres incidentes más costosos del trimestre.”
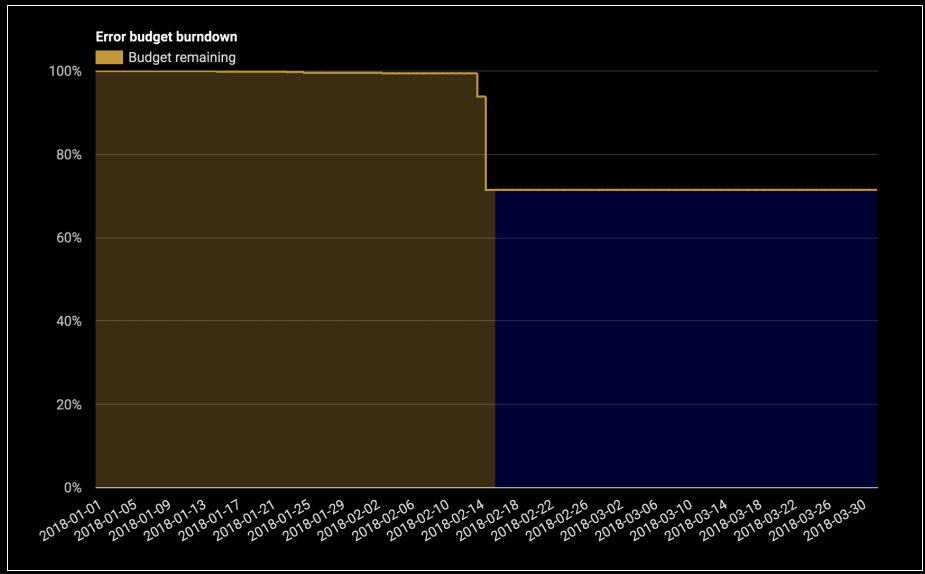
Mejora continua de los objetivos SLO
Todo servicio puede beneficiarse de la mejora continua, un principio central en marcos como ITIL.
🔄 ¿Cómo mejorar los SLO?
Antes de ajustar o mejorar tus SLOs, necesitás una fuente confiable de información sobre la satisfacción del usuario con tu servicio.
📥 Fuentes de información posibles:
- Contar interrupciones detectadas manualmente, publicaciones en foros, tickets de soporte y llamadas al servicio al cliente.
- Medir el sentimiento de los usuarios en redes sociales.
- Incluir código que mida periódicamente la satisfacción del usuario en tu sistema.
- Realizar encuestas cara a cara o muestreos a usuarios reales.
🧭 Recomendación
- Empezá con una métrica económica y fácil de obtener.
- Iterá desde ahí a métodos más sofisticados si es necesario.
- Una buena idea inicial es pedir al product manager que incluya la confiabilidad en las conversaciones que ya tiene con clientes sobre precios y funcionalidad.
Mejorar la calidad de tu SLO
Para evaluar la calidad de un SLO, es útil analizar:
- Cortes de servicio detectados manualmente.
- Tickets de soporte recibidos.
- Incidentes conocidos y su correlación con caídas en el presupuesto de errores.
- Problemas reflejados en los SLIs o quiebre del SLO.
💡 Si sabés algo de estadística, podés usar el coeficiente de correlación de Spearman para cuantificar la relación entre pérdida de presupuesto y tickets/incidentes.
📉 Análisis de correlación
Un gráfico útil es el que compara:
- 📅 Número de tickets por día.
- 📊 Pérdida de presupuesto de errores ese mismo día.
Esto ayuda a encontrar inconsistencias como:
- Un día con pocos tickets pero alta pérdida de presupuesto.
- Un día con muchos tickets pero sin impacto en el presupuesto.
Ambos casos ameritan investigación.
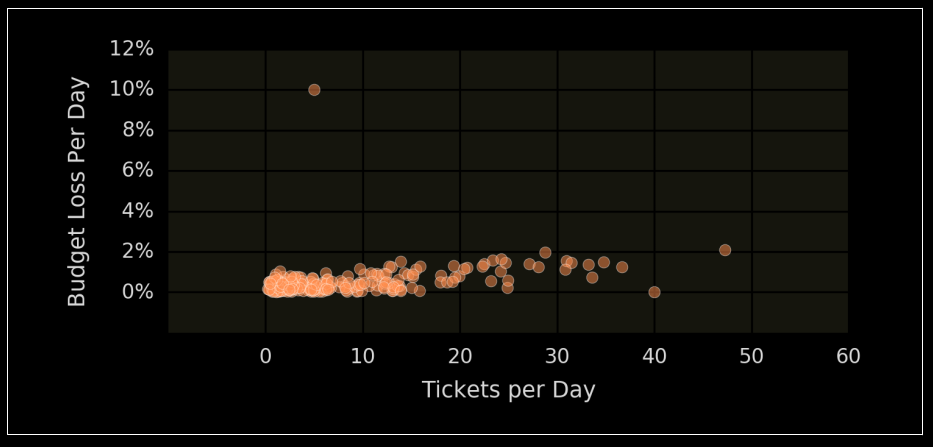
🕵️♂️ ¿Tu SLO no cubre todo?
Si hay:
- Incidentes o picos de tickets no reflejados en SLIs/SLOs.
- Caídas de SLIs sin impacto visible en los usuarios.
Entonces tu SLO probablemente carece de cobertura. Esto es normal al principio, y tus SLIs/SLOs deben evolucionar con el servicio.
🧰 Acciones posibles para mejorar la cobertura
1. Cambiar el SLO
- Si los SLIs indican un problema pero el SLO no genera alertas, quizá deba ajustarse.
- Simulá qué pasaría si usaras ese SLO con tus datos históricos.
- Tené en cuenta el balance entre recall y precisión: más alertas útiles sin saturar al equipo con falsos positivos.
- Si hay muchas falsas alertas o muchas omisiones, quizás el problema esté en el SLI.
2. Mejorar la implementación del SLI
Podés:
- Mover la medición más cerca del usuario (ej. del servidor al cliente o al balanceador de carga).
- Aumentar la cobertura: medir más interacciones del usuario.
- Cambiar métricas simples (ej.
GET /) por pruebas más completas, como un handler que ejercite todo el flujo.
3. Definir un SLO aspiracional
Si necesitás un SLO más exigente pero todavía no podés cumplirlo:
- Mantenelo como aspiracional: lo medís y lo informás, pero no exige acciones si se incumple.
- Te permite ver el progreso hacia ese objetivo sin vivir en modo crisis.
4. Iterar
La mejora es continua. En cada revisión del SLO:
- Elegí el cambio que más beneficio aporte con el menor costo.
- Al principio, preferí soluciones rápidas y baratas, para validar si necesitás invertir más.
- Iterá tantas veces como sea necesario.
Toma de decisiones usando SLOs y presupuestos de errores
Una vez que tenés SLOs definidos, podés usarlos como base para tomar decisiones.
⚠️ ¿Qué hacer si no cumplís con tu SLO?
Cuando se agota el presupuesto de errores, la política correspondiente debería indicar qué hacer. Acciones comunes incluyen:
- Detener nuevos lanzamientos hasta recuperar el cumplimiento del SLO.
- Asignar tiempo de ingeniería exclusivamente a solucionar problemas de confiabilidad.
- En casos extremos, declarar una emergencia que permita rechazar demandas externas hasta que el servicio se estabilice.
También se puede evaluar la gravedad del incidente según el porcentaje del presupuesto consumido.
📊 Ejemplo:
- Un release defectuoso genera
NullPointerExceptionsdurante 4 horas → 14,066 errores → 13% del presupuesto. - Una falla en la base de datos provoca 72,000 errores durante la restauración → 65% del presupuesto.
Aunque una base de datos puede fallar raramente, los lanzamientos fallidos ocurren con más frecuencia. Entonces, mejorar el proceso de release puede tener mayor impacto que optimizar la restauración de la base de datos.
📥 Optimización del esfuerzo
Si un servicio funciona sin problemas y no requiere mucha atención, se puede pasar a un soporte menos intensivo. Esto libera tiempo de SRE para enfocarse en servicios más problemáticos.
🧮 Matriz de decisión basada en SLOs
| SLOs | Esfuerzo | Satisfacción del cliente | Acción sugerida |
|---|---|---|---|
| Cumplido | Bajo | Alta | Relajar despliegues y aumentar velocidad, o reasignar esfuerzos a servicios más críticos. |
| Cumplido | Bajo | Baja | Ajustar (endurecer) el SLO. |
| Cumplido | Alto | Alta | Si hay falsos positivos, reducir sensibilidad de alertas. Si no, aflojar temporalmente el SLO y mejorar el producto o la mitigación automatizada. |
| Cumplido | Alto | Baja | Ajustar (endurecer) el SLO. |
| Fallido | Bajo | Alta | Relajar (aflojar) el SLO. |
| Fallido | Bajo | Baja | Aumentar la sensibilidad de alertas. |
| Fallido | Alto | Alta | Relajar (aflojar) el SLO. |
| Fallido | Alto | Baja | Reducir toil, arreglar el producto y/o mejorar la mitigación automatizada. |
Modelado de recorridos críticos del usuario (User Journeys)
Aunque todas las técnicas vistas ayudan a tu organización, los SLOs deben centrarse en mejorar la experiencia del cliente. Por eso, deben definirse en función de acciones del usuario.
🧭 ¿Qué es un recorrido crítico del usuario?
Un recorrido crítico del usuario es una secuencia de tareas esenciales para la experiencia del usuario y el servicio. Ejemplos en un e-commerce:
- 🔎 Buscar un producto
- 🛒 Agregar un producto al carrito
- 💳 Finalizar una compra
Estos flujos no se corresponden directamente con SLIs existentes, ya que cada acción incluye múltiples pasos que pueden fallar, y es difícil detectar el éxito o fallo a partir de logs.
🐱 Por ejemplo, ¿cómo sabés si el usuario falló en el paso 3 o simplemente se distrajo viendo videos de gatos?
🎯 Paso 1: Identificar lo que importa al usuario
Antes de mejorar la confiabilidad de un servicio, necesitás saber qué acciones son significativas para el usuario.
📏 Paso 2: Medir eventos centrados en el usuario
Una vez identificados, podés buscar formas de medir estos eventos, como por ejemplo:
- Juntar eventos de logs distintos.
- Uso de JavaScript avanzado para rastreo.
- Instrumentación del lado del cliente.
Una vez que se pueden medir, estos eventos pueden convertirse en nuevos SLIs, monitoreados junto a los existentes.
📈 Modelar recorridos críticos del usuario mejora la recall del sistema sin sacrificar precisión.
🆚 Diferencias entre User Journey y User Stories
🧭 User Journey (Viaje del Usuario)
¿Qué es?
Una representación visual o narrativa de los pasos que sigue un usuario para alcanzar un objetivo dentro de un sistema o producto.
Objetivo:
Comprender la experiencia completa del usuario, incluyendo emociones, frustraciones y oportunidades de mejora.
Características:
- Se centra en todo el proceso, no solo en el uso del software.
- Incluye fases como descubrimiento, consideración, decisión, uso, post-uso.
- A menudo se representa como un mapa con etapas, acciones, pensamientos y sentimientos.
Ejemplo:
Juan quiere pagar una multa online. Busca la web, encuentra el sitio, intenta ingresar su patente, tiene problemas con el captcha, logra pagar, recibe confirmación por mail.
📋 User Story (Historia de Usuario)
¿Qué es?
Una descripción breve y estructurada de una necesidad o funcionalidad desde la perspectiva del usuario.
Objetivo:
Definir requisitos funcionales en lenguaje simple y enfocado al valor de negocio.
Formato típico:
Como [tipo de usuario],
quiero [acción o necesidad],
para [beneficio o resultado deseado].
Características:
- Utilizada en metodologías ágiles (como Scrum).
- Enfocada en qué se necesita y por qué, no en cómo se implementa.
- Es una unidad de trabajo para el equipo de desarrollo.
Ejemplo:
Como ciudadano,
quiero poder ingresar mi patente para ver mis multas,
para pagarlas fácilmente desde la web.
📊 Comparación
| Aspecto | User Journey | User Story |
|---|---|---|
| Enfoque | Experiencia completa del usuario | Requisito funcional específico |
| Nivel de detalle | Macro (varias etapas) | Micro (una necesidad puntual) |
| Representación | Narrativa o visual (mapas, diagramas) | Texto estructurado |
| Uso principal | Diseño UX, descubrimiento, empatía | Desarrollo ágil, priorización de tareas |
| Incluye emociones | Sí | No (se centra en funcionalidad) |
🎯 ¿Cuándo usar cada una?
-
Usa User Journey cuando quieras:
- Entender el contexto y emociones del usuario.
- Detectar puntos de dolor y oportunidades de mejora.
- Diseñar experiencias de usuario más completas.
-
Usa User Stories cuando quieras:
- Planificar y desarrollar funcionalidades concretas.
- Dividir el trabajo en tareas claras para el equipo técnico.
- Priorizar en un backlog ágil.
- Los SLOs deben reflejar experiencias reales del usuario.
- Los recorridos críticos del usuario ayudan a identificar lo que realmente importa.
- Aunque difíciles de medir, se pueden instrumentar con herramientas avanzadas.
- Medir y rastrear estos eventos permite crear SLIs más relevantes y efectivos.
Clasificación de la importancia de las interacciones
No todas las solicitudes HTTP son iguales. Por ejemplo:
- Una solicitud desde la app móvil para ver notificaciones puede ser útil...
- ...pero no tan crítica como una solicitud de facturación de un anunciante.
🎯 ¿Qué hacer?
Necesitamos una forma de distinguir clases de solicitudes. Esto se puede lograr mediante:
- Bucketing: agregar etiquetas (labels) adicionales a tus SLIs y aplicar SLOs diferenciados por etiqueta.
📊 Tabla 2-6. Agrupamiento por tipo de cliente
| Tipo de cliente | SLO de disponibilidad |
|---|---|
| Premium | 99.99% |
| Free (gratis) | 99.9% |
🕒 Tabla 2-7. Agrupamiento por expectativa de respuesta
| Tipo de respuesta | SLO de latencia |
|---|---|
| Interactiva (ej. bloquea la carga de la página) | 90% de las solicitudes completan en 100 ms |
| Descarga de CSV | 90% de las descargas inician dentro de 5 s |
📈 Aplicación por cliente
Si tenés datos suficientes, podés aplicar SLOs por cliente y rastrear cuántos están cumpliendo su SLO en tiempo real.
⚠️ Pero este dato puede ser muy variable, especialmente para clientes con pocos requests:
- Con 1 sola falla pueden quedar fuera del SLO.
- O pueden estar al 100% por pura suerte.
Por eso es más útil observar patrones agregados: ¿cuántos clientes están incumpliendo SLO por razones comunes o compartidas?
Modelado de dependencias
Los sistemas grandes tienen múltiples capas (presentación, aplicación, lógica de negocio, persistencia), cada una compuesta por uno o varios servicios/microservicios.
Aunque el objetivo principal es definir un SLO centrado en el usuario que cubra todo el stack, también podés usar SLOs para coordinar requisitos de confiabilidad entre componentes.
🔗 Dependencias críticas
Si un componente es crítico para una interacción valiosa, su SLO debe ser tan estricto como el de la acción que depende de él.
- El equipo responsable del componente debe gestionar su propio SLO como parte del SLO global del producto.
Si un componente tiene limitaciones inherentes de confiabilidad, el SLO puede comunicarlo. En ese caso, si la interacción requiere más disponibilidad que la que ese componente puede ofrecer, hay que ingeniar soluciones:
🛠️ Posibles soluciones:
- Usar otro componente.
- Implementar defensas como:
- Caché
- Procesamiento offline
- Store-and-forward
- Degradación controlada
🤔 ¿Duplicar zonas = mayor disponibilidad?
Ejemplo: un servicio tiene 99.9% en una zona. ¿Desplegarlo en dos zonas da 99.9999%?
Cuidado: esto asume independencia total entre zonas, lo cual rara vez ocurre.
Motivos por los que ambas zonas pueden fallar simultáneamente:
- Dependencias comunes
- Dominios de falla compartidos
- Planes de control globales
- Fallos coordinados por diseño
✋ A menos que documentes y consideres cada dependencia, esos cálculos pueden ser engañosos.
🧭 Políticas de presupuesto ante fallas externas
Cuando se incumple un SLO por culpa de una dependencia manejada por otro equipo, hay dos enfoques posibles:
1. "No es nuestra culpa"
- El equipo no toma acción (no congela lanzamientos ni dedica más tiempo a confiabilidad).
2. "Igual cuidamos al usuario"
- Se aplica una congelación de cambios para reducir riesgo, aunque la falla no sea propia.
✅ Este segundo enfoque beneficia más a los usuarios.
⚙️ La aplicación depende del contexto: si congelar cambios no es viable, se puede definir otra acción. Lo importante es documentar la decisión en la política de presupuesto.
Experimentar relajando tus SLOs
Podés querer experimentar con la confiabilidad de tu aplicación y observar cómo ciertos cambios (por ejemplo, agregar latencia) afectan el comportamiento del usuario (como la tasa de compras completadas).
⚠️ Este tipo de análisis debe hacerse solo si tenés presupuesto de errores disponible. La relación entre latencia, disponibilidad, usuarios, contexto de negocio y competencia puede ser compleja y delicada.
🧪 ¿Por qué hacer estos experimentos?
Aunque da miedo (¡nadie quiere perder ventas!), los resultados pueden darte insights valiosos que:
- Ayuden a mejorar el servicio en el futuro.
- Permitan identificar una relación cuantificable entre una métrica técnica (como la latencia) y un indicador de negocio (como ventas).
Esto te permite tomar decisiones de ingeniería más informadas.
🔁 No es un experimento único
Tus usuarios y tu producto evolucionan constantemente, así que:
- Repetí estos análisis periódicamente.
- Validá que las relaciones observadas sigan siendo válidas.
⚠️ Riesgos a tener en cuenta
- Podés interpretar mal los datos. Ejemplo:
Añadís 50 ms de latencia ➝ no baja la conversión ➝ pensás que tu SLO es muy estricto.
Pero en realidad:
- Tus usuarios podrían estar insatisfechos pero sin alternativas en ese momento.
- Si aparece competencia, se irán.
👉 Asegurate de medir los indicadores correctos y tomar las precauciones adecuadas.
📄 Documento de SLO – Ejemplo
🧾 Metadatos
| Campo | Valor |
|---|---|
| Autor | Steven Thurgood |
| Fecha | 2018-02-19 |
| Revisores | David Ferguson |
| Aprobadores | Betsy Beyer |
| Fecha de Aprobación | 2018-02-20 |
| Fecha de Revisión | 2019-02-01 |
📄 Documento de SLO – Ejemplo
🧾 Metadatos
| Campo | Valor |
|---|---|
| Autor | Steven Thurgood |
| Fecha | 2018-02-19 |
| Revisores | David Ferguson |
| Aprobadores | Betsy Beyer |
| Fecha de Aprobación | 2018-02-20 |
| Fecha de Revisión | 2019-02-01 |
⚙️ SLI / SLO por categoría
API
| Métrica | SLI | SLO |
|---|---|---|
| Disponibilidad | Proporción de solicitudes exitosas (status < 500) según métricas del balanceador de carga. count(api_requests sin 5XX) / count(total api_requests) | 97% de éxito |
| Latencia | Proporción de solicitudes rápidas. Definición de "rápido": < 400 ms o < 850 ms. - count(api_requests <= 0.4s) / total - count(api_requests <= 0.85s) / total | 90% < 400 ms 99% < 850 ms |
Servidor HTTP
| Métrica | SLI | SLO |
|---|---|---|
| Disponibilidad | Igual que API, pero para tráfico "web". count(web_requests sin 5XX) / count(total web_requests) | 99% de éxito |
| Latencia | Solicitudes rápidas definidas como < 200 ms o < 1000 ms. - count(web_requests <= 0.2s) / total - count(web_requests <= 1.0s) / total | 90% < 200 ms 99% < 1000 ms |
📊 Ejemplo: Pipeline de puntajes
| Categoría | SLI (Indicador de Nivel de Servicio) | SLO (Objetivo de Nivel de Servicio) |
|---|---|---|
| Frescura | Proporción de registros leídos de la tabla de posiciones que fueron actualizados recientemente. “Recientemente” se define como dentro de 1 minuto o dentro de 10 minutos. Usa métricas de la API y el servidor HTTP:cantidad de solicitudes de datos para "api" y "web" con frescura ≤ 1 minuto / cantidad total de solicitudes``cantidad de solicitudes de datos para "api" y "web" con frescura ≤ 10 minutos / cantidad total de solicitudes | 90% de las lecturas usan datos escritos en el último minuto. 99% de las lecturas usan datos escritos en los últimos 10 minutos. |
| Corrección | Proporción de registros inyectados en la tabla de estado por una sonda de corrección que resultan en datos correctos al ser leídos de la tabla de posiciones. Una sonda de corrección inyecta datos sintéticos, con resultados conocidos como correctos, y exporta una métrica de éxito:cantidad de solicitudes correctas / cantidad total de solicitudes | 99.99999% de los registros inyectados por la sonda resultan en datos correctos. |
| Completitud | Proporción de horas en las que el 100% de los partidos en el almacén de datos fueron procesados (sin omitir registros). Usa métricas exportadas por el pipeline de puntuación:cantidad de ejecuciones del pipeline que procesaron el 100% de los registros / cantidad total de ejecuciones del pipeline | 99% de las ejecuciones del pipeline cubren el 100% de los datos. |