Diferencias de metricas a nivel de servicio

✅ SLA (Service Level Agreement Acuerdo de Nivel de Servicio)
- Definición: Acuerdo formal entre proveedor y cliente (generalmente de pago). Establece métricas como tiempo de actividad, tiempos de respuesta y responsabilidades, así como sanciones por incumplimiento.
-
Desafíos:
- Suelen ser redactados por equipos legales sin conocimiento técnico.
- Pueden contener definiciones vagas o difíciles de medir (por ejemplo, ¿cuándo empieza a contarse el tiempo de respuesta?).
-
Cuándo se usa: Solo se aplica a clientes de pago. Los servicios gratuitos no suelen tener SLA.
🎯 SLO (Service Level Objective Objetivo de Nivel de Servicio)
-
Definición: Objetivos específicos y medibles dentro de un SLA. Ejemplo: “Disponibilidad del 99,95 %” o “Respuesta menor a 300 ms”.
-
Desafíos:
- Deben ser pocos, simples y claros.
- Demasiados objetivos pueden confundir al equipo.
-
Cuándo se usa: Se usan con o sin SLA. Son útiles para monitorear tanto servicios públicos como sistemas internos.
📈 SLI (Service Level Indicator Indicador de Nivel de Servicio)
-
Definición: Métrica real que mide el desempeño del sistema. Ejemplo: “La disponibilidad fue del 99,96 %”.
-
Desafíos:
- Elegir métricas relevantes, evitar métricas innecesarias.
- Medir bien para saber si se cumple el SLO.
-
Cuándo se usa: Siempre que querés saber si estás cumpliendo tus SLO (y por tanto, el SLA si aplica).
🧩 Comparación rápida
| Concepto | Naturaleza | Rol principal |
|---|---|---|
| SLA | Acuerdo formal | Promesa legal con sanciones por incumplimiento |
| SLO | Objetivo cuantificable | Define lo que esperás lograr |
| SLI | Métrica real | Mide si cumplís con el objetivo |
🛠️ Buenas prácticas
- Diseñar el SLA con foco en lo que le importa al cliente.
- Usar lenguaje claro y accesible.
- Mantener pocos SLO bien definidos.
- Elegir solo los SLIs necesarios.
- Considerar retrasos que no dependen del proveedor (ej: cliente tarda en responder).
- Definir un error budget para permitir cierta flexibilidad.
- No sobreprometer. Es mejor superar expectativas que incumplir promesas.
Veamos ahora mas en profundidad estos conceptos.
Objetivos de Nivel de Servicio (SLO)
- Para gestionar correctamente un servicio, es clave entender qué comportamientos importan, cómo medirlos y evaluarlos.
- Se busca definir y ofrecer un nivel de servicio a los usuarios, ya sea usando APIs internas o productos públicos.
- Se utilizan tres conceptos fundamentales:
- SLI (Indicador de Nivel de Servicio): Métrica que refleja el rendimiento del servicio.
- SLO (Objetivo de Nivel de Servicio): Valor que se espera alcanzar con esa métrica.
- SLA (Acuerdo de Nivel de Servicio): Compromiso formal basado en el SLO.
- Elegir las métricas correctas ayuda a detectar fallas, tomar acciones correctivas y dar confianza sobre el estado del servicio.
- El capítulo presenta un marco para modelar, seleccionar y analizar métricas, usando un ejemplo concreto (Shakespeare: A Sample Service).
🧾 Terminología
- Aunque SLA es el término más conocido, SLI y SLO requieren definiciones claras.
- El término SLA puede estar sobrecargado y variar según el contexto, por eso se prefiere separarlos conceptualmente.
📊 Indicadores (SLI)
- Un SLI (Service Level Indicator) es una métrica cuantitativa que mide un aspecto específico del nivel de servicio ofrecido.
- Ejemplos comunes:
- Latencia de respuesta (request latency): Tiempo que tarda en responder una solicitud.
- Tasa de errores (error rate): Proporción de solicitudes fallidas.
- Rendimiento del sistema (throughput): Solicitudes por segundo.
- Estas métricas suelen agregarse en promedios, tasas o percentiles.
- A veces se usan proxies si la métrica deseada es difícil de obtener (ej: medir la latencia en el cliente puede requerir inferirla desde el servidor).
- Otro SLI clave es la disponibilidad (availability): Fracción del tiempo en que el servicio es utilizable.
- Puede expresarse como el porcentaje de solicitudes exitosas (yield).
- Ejemplos comunes:
- 99% → “2 nueves”
- 99.999% → “5 nueves”
- Google Compute Engine apunta a 99.95% ("tres nueves y medio").
🎯 Objetivos (SLO)
- Un SLO (Service Level Objective) es un valor o rango objetivo que un SLI debe cumplir.
- Estructura típica:
límite inferior ≤ SLI ≤ límite superior. - Ejemplo: “La latencia promedio de búsqueda debe ser menor a 100 ms”.
- Estructura típica:
- Elegir un SLO adecuado puede ser complejo:
- No siempre se puede definir un SLO para todas las métricas (ej: consultas por segundo dependen del usuario).
- Pero sí se puede decir: “Queremos que el 95% de las respuestas estén bajo los 100 ms”.
- Establecer SLOs ambiciosos puede motivar mejoras técnicas (ej: usar cachés, optimizar frontend, etc).
- A veces los SLIs están conectados de forma indirecta. Por ejemplo: un mayor QPS (consultas por segundo) puede generar mayor latencia, y muchos servicios presentan un desempeño crítico cuando se superan ciertos límites de carga.
- Publicar SLOs ayuda a gestionar expectativas de los usuarios sobre el rendimiento del servicio.
- Reduce quejas infundadas (ej: “el servicio está lento”).
- Sin un SLO claro, los usuarios se hacen su propia idea del rendimiento deseado, que puede no coincidir con la visión del equipo técnico.
- Esto puede causar:
- Sobreconfianza: creer que el servicio es más confiable de lo que es (ej: Chubby y su apagado planificado).
- Desconfianza: pensar que el sistema es menos confiable de lo que realmente es.
📜 Acuerdos (SLA)
-
Un SLA (Service Level Agreement) es un contrato explícito o implícito con los usuarios que establece consecuencias si los SLOs se cumplen o no.
- Las consecuencias más comunes son financieras (ej: descuentos, penalizaciones).
-
🔍 Diferencia clave entre SLO y SLA:
- Pregunta útil: ¿Qué pasa si no se cumple?
- Si no hay consecuencias explícitas, es un SLO, no un SLA.
-
El equipo SRE no suele crear SLAs, ya que están ligados a decisiones de negocio.
Sin embargo, sí:
- Ayudan a evitar consecuencias por SLOs incumplidos.
- Definen métricas objetivas (SLIs) para evitar desacuerdos.
-
🧠 Ejemplo: Google Search
- No tiene SLA con el público, pero igual se preocupa por su disponibilidad.
- Si Search cae, impacta en la reputación y los ingresos por publicidad.
- Servicios como Google for Work sí tienen SLAs explícitos.
💡 Independientemente de tener SLA o no, siempre es útil definir SLIs y SLOs para gestionar correctamente un servicio.
🧪 Indicadores en la práctica
🎯 ¿Qué métricas importan para vos y tus usuarios?
- No todo lo que se puede medir debe convertirse en un SLI.
- Es clave entender qué valoran tus usuarios para seleccionar solo algunos indicadores relevantes.
⚖️ Buen balance
- Demasiados indicadores: se pierde foco y atención en los que realmente importan.
- Muy pocos indicadores: pueden quedar fuera comportamientos importantes del sistema.
✅ Lo ideal: Un puñado de indicadores representativos suelen ser suficientes para evaluar la salud del sistema de forma efectiva.
¹ La mayoría de las personas dicen "SLA" pero en realidad se refieren a un SLO. Una violación real de SLA puede implicar acciones legales por incumplimiento de contrato.
🧩 Categorías comunes de SLIs
Los servicios suelen agruparse en categorías según los SLIs que consideran más relevantes:
- Sistemas orientados al usuario (como buscadores):
- Se enfocan en: disponibilidad, latencia y rendimiento (throughput).
- Preguntas clave: ¿Se respondió al usuario? ¿Cuánto tardó? ¿Cuántas solicitudes se pudieron manejar?
- Sistemas de almacenamiento:
- Enfatizan: latencia, disponibilidad y durabilidad.
- ¿Cuánto tarda en leerse o escribirse un dato? ¿Está disponible cuando lo necesitamos?
- Sistemas de big data:
- Se preocupan por: throughput y latencia de punta a punta.
- ¿Cuánto se procesa? ¿Cuánto demora desde la entrada hasta el resultado?
- *Todos los sistemas deberían considerar la corrección:
- ¿Se devolvió la respuesta correcta? ¿El análisis fue el esperado?
- Aunque no siempre es responsabilidad directa del SRE, es un buen indicador de salud del sistema.
🕵️♂️ Recolección de Indicadores
- Las métricas se suelen recopilar en el servidor usando herramientas como Prometheus o Borgmon, o mediante análisis de logs.
- Ejemplo: proporción de respuestas HTTP 500.
- Sin embargo, algunos sistemas deben medir desde el cliente:
- Medir solo en el servidor puede ocultar problemas reales del usuario.
- Ejemplo: latencia baja en backend de búsqueda pero mala experiencia por un error en el frontend (JavaScript).
🔍 Medir desde el cliente puede ofrecer una visión más precisa de la experiencia real del usuario.
📊 Agregación de Métricas
- Para simplificar y facilitar el análisis, solemos agregar mediciones crudas, pero esto debe hacerse con cuidado.
- Incluso métricas simples como solicitudes por segundo ocultan detalles:
- ¿Se mide cada segundo? ¿O es un promedio por minuto?
- Un promedio puede esconder ráfagas (ej: 200 req/s en pares y 0 en impares vs. 100 constantes).
- Lo mismo aplica para la latencia promedio:
- Puede parecer buena, pero puede haber una "cola larga" de solicitudes con latencias mucho mayores.
- Por eso, las distribuciones son mejores que los promedios.
Ejemplo:
- Una latencia promedio de 50ms puede ocultar que el 5% de las solicitudes son 20 veces más lentas.
- Un gráfico como el de la Figura 4-1 muestra latencias por percentil:
- 50 (mediana), 85, 95, y 99% para observar tanto el caso típico como el peor caso.
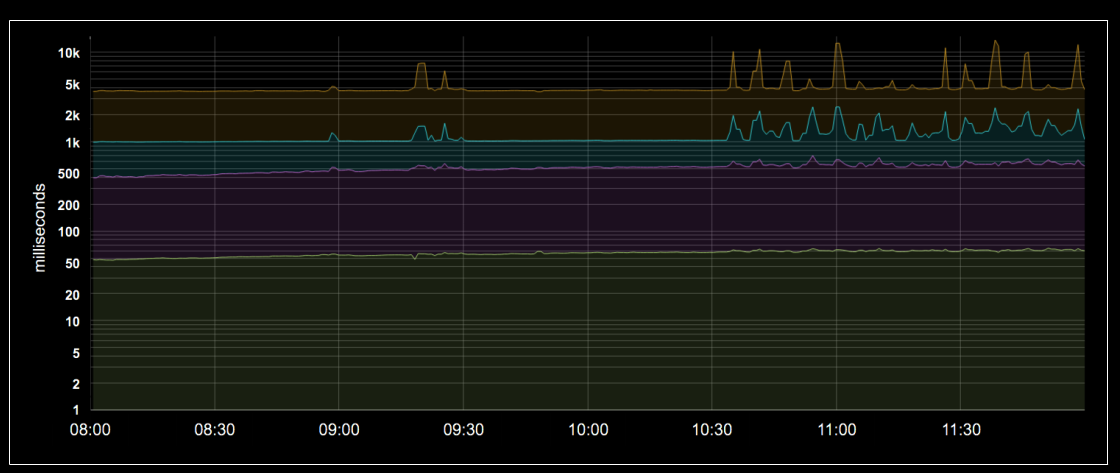
🎯 Uso de Percentiles
- Los percentiles permiten observar la forma de la distribución:
- Percentiles altos (99%, 99.9%) → muestran posibles casos extremos (peor caso).
- Percentil 50 (mediana) → representa el caso típico.
- Cuanto mayor es la varianza en los tiempos de respuesta, más afectada se ve la experiencia de usuario.
- En cargas altas, esta variabilidad empeora por efectos de colas y espera.
📌 Estudios indican que la gente prefiere un sistema ligeramente más lento pero constante, que uno rápido pero inestable.
Por eso, muchos equipos SRE se enfocan en los percentiles altos:
Si el 99.9% de las solicitudes son buenas, la experiencia típica también lo será.
⚠️ Nota sobre Falacias Estadísticas
- Es preferible usar percentiles en lugar del promedio (media aritmética) para describir datos.
- Permite considerar la cola larga de los datos, donde suelen estar los casos más interesantes o extremos.
- En sistemas computacionales, los datos suelen estar sesgados:
- No puede haber tiempos de respuesta menores a 0 ms.
- Si hay un timeout de 1000 ms, no puede haber respuestas mayores a ese valor.
❗ Por eso, no se debe asumir que media y mediana son iguales o cercanas.
- Tampoco debemos suponer que los datos tienen una distribución normal sin comprobarlo.
- Si se basan decisiones automáticas en esa suposición (ej: reiniciar un servidor por latencias altas), puede que se actúe demasiado o muy poco.
📌 La verificación empírica es clave para no caer en errores de interpretación estadística.
📏 Estandarizar Indicadores
- Usar definiciones comunes para los SLIs ahorra esfuerzo y facilita su comprensión.
- Cualquier aspecto que siga una plantilla estándar puede omitirse al definir un SLI.
- Ejemplos:
- Intervalos de agregación: "Promediado cada 1 minuto"
- Región: "Todas las tareas de un clúster"
- Frecuencia: "Cada 10 segundos"
- Solicitudes incluidas: "HTTP GETs desde monitores tipo black-box"
- Fuente de datos: "Medido en el servidor"
- Latencia de acceso: "Tiempo hasta el último byte"
- Ejemplos:
🔁 Crear plantillas reutilizables para SLIs comunes facilita su uso y evita malentendidos.
🛠 Objetivos en la Práctica
- Comenzá pensando en qué les importa a los usuarios, no solo en lo que podés medir.
- A veces lo que más importa es difícil de medir, y se termina usando aproximaciones.
- Si solo usás lo fácil de medir, obtendrás SLOs menos útiles.
🔄 A veces es mejor partir del objetivo deseado y de ahí definir los indicadores, en lugar de al revés.
🎯 Definir Objetivos
- Los SLOs deben especificar cómo se miden y bajo qué condiciones son válidos.
- Ejemplo de SLO:
- “El 99% de las llamadas RPC GET se completarán en menos de 100 ms, promediado por minuto y medido en todos los servidores.”
- Se pueden usar múltiples objetivos para reflejar distintas partes de la curva de rendimiento:
- 90% de llamadas < 1 ms
- 99% < 10 ms
- 99.9% < 100 ms
- Para sistemas con distintos tipos de usuarios (ej: batch vs interactivo), podés definir SLOs separados:
- 95% de clientes por rendimiento: llamadas < 1 s
- 99% de clientes sensibles a latencia (menor a 1kB): llamadas < 10 ms
📉 Tolerancia a Errores (Error Budget)
- Es irreal e innecesario esperar cumplir los SLOs el 100% del tiempo.
- Se recomienda permitir un presupuesto de error (error budget) y hacer seguimiento diario/semanal.
- Alta dirección puede querer informes mensuales/trimestrales.
- La tasa de incumplimiento de SLOs es un indicador clave de salud del servicio.
🔁 La tasa de violaciones se compara contra el presupuesto de error, y puede usarse para decidir si lanzar nuevas versiones o no.
🎯 Elección de Objetivos (SLOs)
Definir objetivos (SLOs) no es solo una tarea técnica; también tiene implicancias de negocio y producto. Algunas lecciones clave:
🛑 No uses el rendimiento actual como objetivo
- Basarse solo en lo que el sistema ya hace puede llevar a soportar soluciones poco sostenibles.
✅ Mantenelo simple
- Agregaciones complicadas pueden ocultar problemas o dificultar el análisis.
🚫 Evitá los absolutos
- Buscar “disponibilidad total” o “latencia cero” no es realista. Estos objetivos requieren mucho tiempo y recursos sin aportar valor real.
🔢 Menos es más
- Usá la menor cantidad de SLOs necesaria para cubrir los aspectos importantes del sistema.
🛠 La perfección puede esperar
- Empezá con objetivos más laxos y afiná con el tiempo a medida que aprendas del comportamiento del sistema.
📋 Medidas de Control
Los SLIs y SLOs son partes esenciales en el control del sistema:
- Monitorizar los SLIs.
- Compararlos con los SLOs.
- Determinar si hay que actuar.
- Actuar en consecuencia.
📌 Ejemplo: Si la latencia está subiendo y va a superar el SLO pronto, evaluá si se debe agregar capacidad o redistribuir carga.
⚖️ Los SLOs fijan expectativas
Publicar SLOs permite a los usuarios saber qué esperar del servicio. Ayuda a:
- Validar si el servicio es adecuado para su uso.
- Evitar sorpresas o malentendidos.
✅ Mantené un margen de seguridad
- Usar un SLO más estricto internamente que el publicado permite reaccionar antes de que los usuarios noten problemas.
❌ No sobrecumplas
- Si el servicio funciona mucho mejor de lo prometido, los usuarios se acostumbran. Esto puede llevar a dependencia excesiva.
- Ejemplo: Google planifica apagones de Chubby para evitar esto.
📌 Si el servicio ya cumple, puede ser mejor enfocar recursos en otras prioridades (deuda técnica, nuevas funciones, etc.).
📝 Acuerdos en la práctica (SLAs)
- Crear un SLA requiere participación de equipos legales y de negocio.
- El rol del SRE es explicar cuán factible es cumplir los SLOs incluidos en el SLA.
- La mayoría de las recomendaciones para definir SLOs también aplican a SLAs.
🛑 Consejo: Sé conservador con lo que prometés. Cuanto más amplio es el público objetivo, más difícil es modificar un SLA mal definido.
Bibliografia adicional:
- https://www.atlassian.com/es/incident-management/kpis/sla-vs-slo-vs-sli
- Site Reliability Engineering (https://sre.google/sre-book/table-of-contents/):
- Betsy Beyer
- Chris Jones
- Jennifer Petoff
- Niall Richard Murphy